


Sanal Devrimin Nükleer Bedeli: Yapay Zekanın Enerji İştahı, Yeni Santraller İnşa Ettiriyor

📰Haftanın Haberleri
Yapay zekanın durdurulamaz enerji talebi, Google'ı radikal bir çözüme itti: Geleceğin gücü nükleer enerjiden gelecek.
Yeni bir araştırma, yapay zekanın en büyük umutlarından RAG'in bile kusurlu olduğunu kanıtladı: Modeller, doğru bilgiyle beslense dahi ikna edici şekilde halüsinasyon görüyor.
Reddit, yapay zeka devi Anthropic'i platformdaki milyonlarca kullanıcının sohbetini izinsiz bir şekilde kullanmakla suçlayarak dava açtı.
Verilerinizin size özel kalmasını sağlayan, tamamen yerel ve açık kaynak olarak çalışan yapay zeka asistanı AgenticSeek, Manus AI'ye güçlü bir alternatif olarak ortaya çıktı.
ChatGPT artık Google Drive ve GitHub gibi uygulamalara doğrudan bağlanarak dosya analizi ve veri çekme işlemlerini tek tıkla yapabiliyor!
❯ Google, Yapay Zekası İçin Üç Yeni Nükleer Santral İnşa Edecek

Yapay zekayla oluşturulan tek bir görüntü, bir akıllı telefonu şarj etmeye yetecek kadar enerji tüketiyor. İnternet kullanıcıları arasında giderek popülerleşen yapay zeka araçlarını çalıştırmak için gereken veri merkezleriyse devasa miktarda enerjiye ihtiyaç duyuyor.
Google'ın bu ihtiyacı gidermek için üç yeni nükleer santral inşa etmeyi planladığı öğrenildi. Nükleer enerji geliştiricisi Elementl Power, Google ile "ileri nükleer enerji" üretimi için üç proje sahası inşa etmek üzere anlaşma imzaladığını duyurdu.
Google'ın veri merkezlerinin enerjisinden sorumlu başkanı Amanda Peterson Corio, "Elementl Power ile yaptığımız iş birliği, yapay zeka ve Amerikan inovasyonuna ayak uydurmak için gereken hızda hareket etme yeteneğimizi artıracak." dedi.
Öte yandan Google'ın gözünü diktiği tek nükleer proje bu değil. Şirket, geçen yıl nükleer enerji sağlayıcısı Kairos Power ile “2035'e kadar toplam 500 megawatt değerinde gelişmiş nükleer enerji projelerinden oluşan bir ABD filosu konuşlandırmak” için anlaşma imzalamıştı.
Yapay zekaya güç veren veri merkezlerinin 2026’ya kadar en büyük beşinci enerji tüketicisi haline gelmesi öngörülüyor. Bu da Google dahil pek çok kurumun nükleer enerjiye gittikçe daha fazla başvuracağı anlamına geliyor.
Mahmut Ali ÖNCEL
Marmara Üniversitesi Yönetim ve Bilişim Sistemleri
❯RAG Çağının Sonu mu Geliyor?
Araştırmacılar, Kusursuz Görünen Modellerin Gerçek Bilgiyle İmtihanını Gözler Önüne Serdi!
Bilgiyle desteklenen yapay zeka yanıtları artık kimseyi kandıramıyor. Cornell, EPFL ve Google DeepMind araştırmacıları tarafından yayımlanan yeni bir çalışma; Bilgiyle Zenginleştirilmiş Yanıtlama(Retrieval Augmented Generation) sistemlerinin, ellerine doğru ve yeterli bağlam verildiğinde bile gerçek dışı bilgiler (halüsinasyon) üretmeye devam ettiğini ortaya koydu. Dahası bu hatalar dışarıdan bakıldığında neredeyse ayırt edilemiyor.
Araştırma; bağlam verilmiş olmasına rağmen modelin hatalı veya uydurma yanıtlar üretebildiğini, üstelik bu yanıtların kullanıcıya “doğruymuş gibi” geldiğini gösteriyor. Bu da RAG sistemlerini sadece teknik açıdan değil, etik ve güvenlik açısından da sorgulanan bir konuma getiriyor.
“Context enough” devri kapanıyor olabilir.
Bugüne kadar RAG mimarileri, büyük dil modellerinin güvenilirliğini arttırmanın yolu olarak görülüyordu. Ancak bu çalışma, modellerin yalnızca bilgiye erişiminin yeterli olmadığını, aynı zamanda o bilgiyi doğru yorumlama ve yansıtma kabiliyetinin de geliştirilmesi gerektiğini vurguluyor.
Araştırmanın çarpıcı bulgularından biri de şu: Halüsinasyonlu çıktılar, kullanıcı testlerinde genellikle “başarılı” olarak puanlandı. Yani model yanlış bile söylese yeterince ikna edici olduğu sürece fark edilmiyor.
Gelecek Senaryosu: RAG 2.0 mı Yoksa Alternatif Paradigmalar mı?
Bu gelişme, model geliştiriciler için önemli bir uyarı niteliğinde. Geliştiricilerin artık sadece bilgiye erişen değil, bilgiyi doğru biçimde işleyebilen ve gerçeklikten sapma riskini izleyebilen sistemler tasarlaması gerekiyor. Aksi takdirde kullanıcı güveni geri dönüşü olmayan şekilde sarsılabilir.
Şu an için hâlâ güçlü bir araç olan RAG modelleri, belki de yeni bir versiyonun eşiğinde. Halüsinasyona karşı bağlamın değil, anlamın ve içsel kontrol mekanizmalarının öne çıktığı bir gelecek bizi bekliyor olabilir.
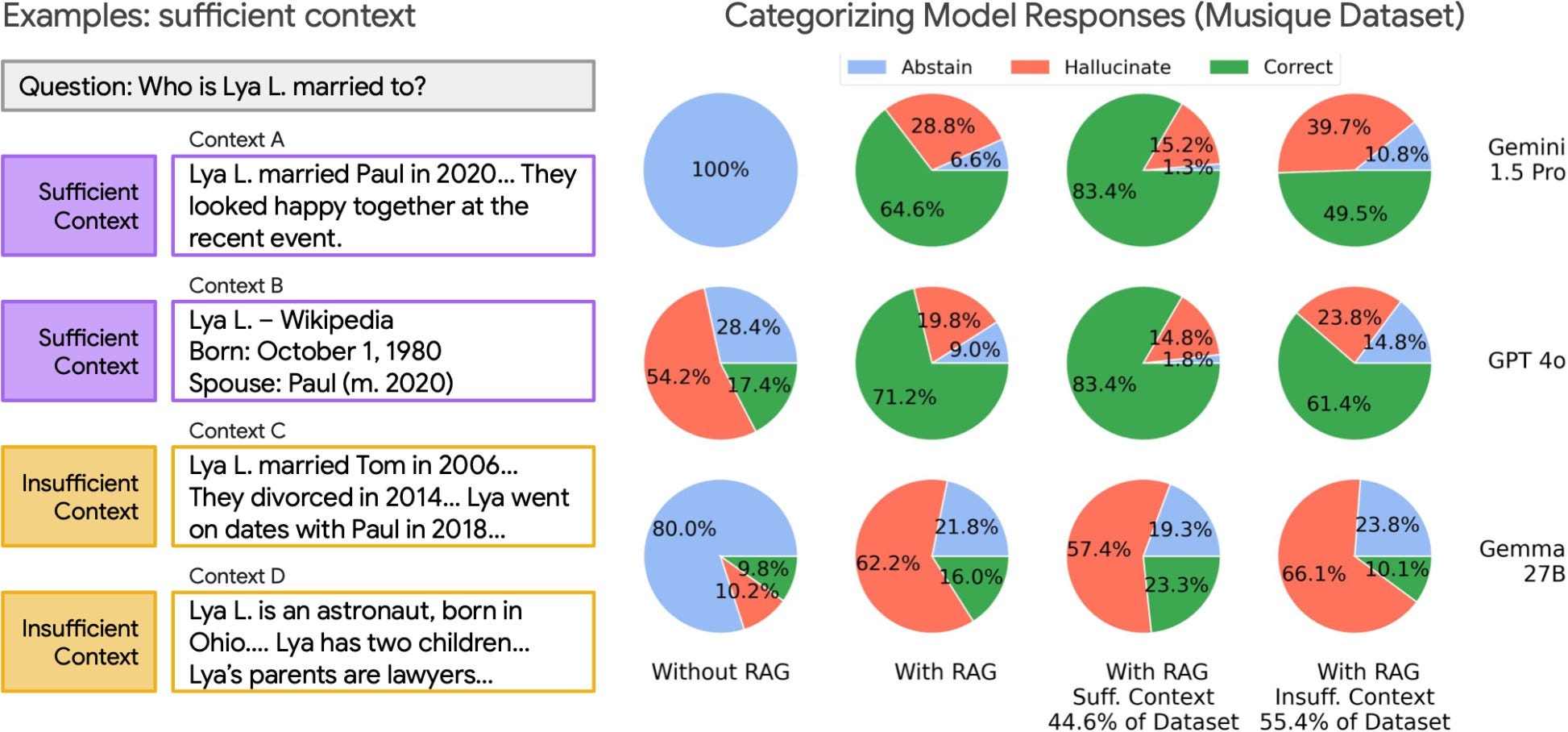
Şekil 1: RAG sistemlerinde bağlam yeterliliği ve model yanıtlarının analizi.
Sol tarafta yeterli bağlama sahip örnekler, sağda ise Musique veri seti üzerinde model yanıtlarının doğruluk ve halüsinasyon dağılımı yer almakta. RAG kullanımı doğruluk oranını arttırsa da bağlam yetersizliğinden bağımsız olarak halüsinasyon üretme eğilimi artmakta. Ayrıca veri setindeki örneklerin büyük bölümü (%55,4) yeterli bağlamdan yoksun.
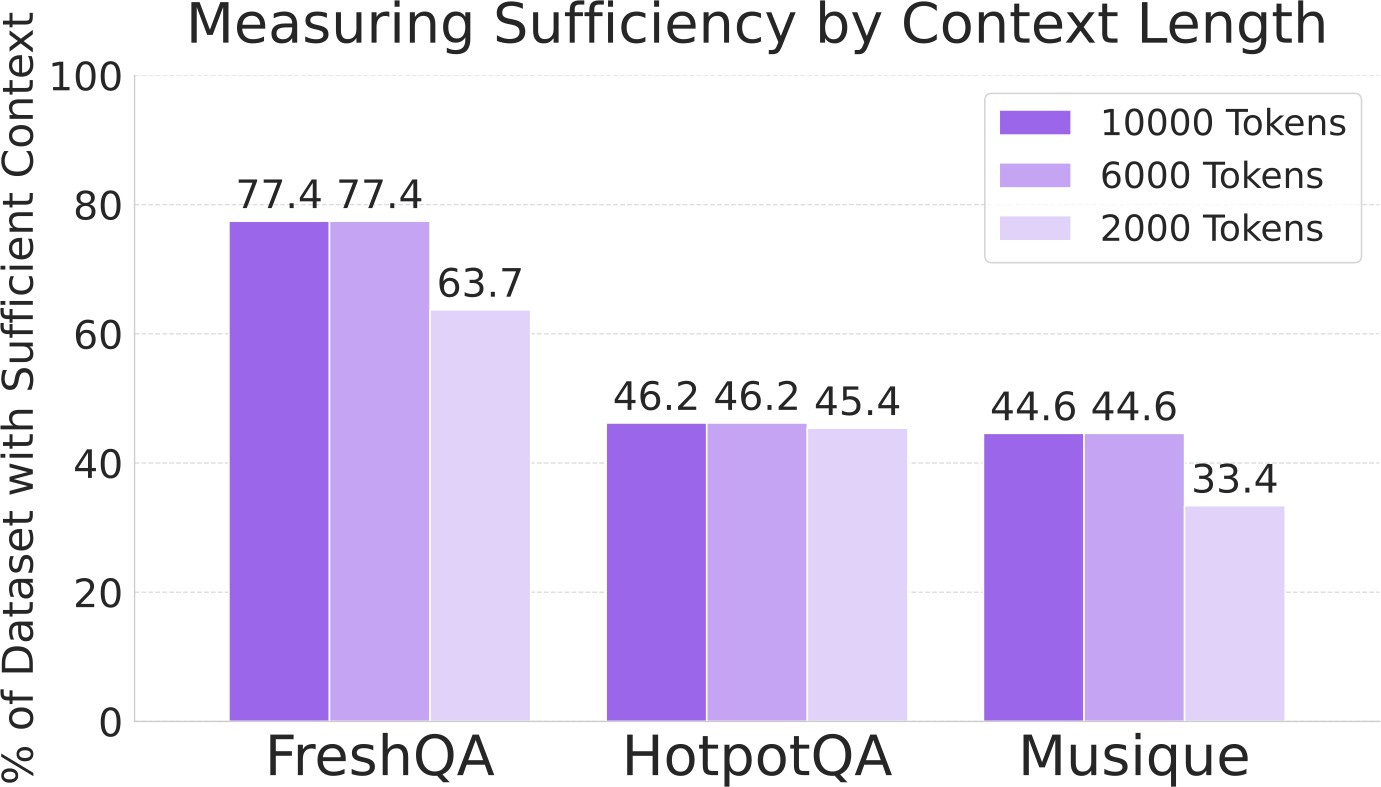
Şekil 2: Farklı bağlam uzunluklarında veri setlerindeki bağlam yeterliliği oranları.
FreshQA, yanıtları destekleyen özenle seçilmiş kaynaklara sahip olduğu için yüksek bağlam yeterliliği göstermekte. HotpotQA ve Musique ise özellikle kısa bağlam uzunluklarında (örneğin 2000 token) daha düşük oranlara sahip. Çalışmanın geri kalanında 6000 tokenlik bağlam uzunluğu tercih edilmiş.
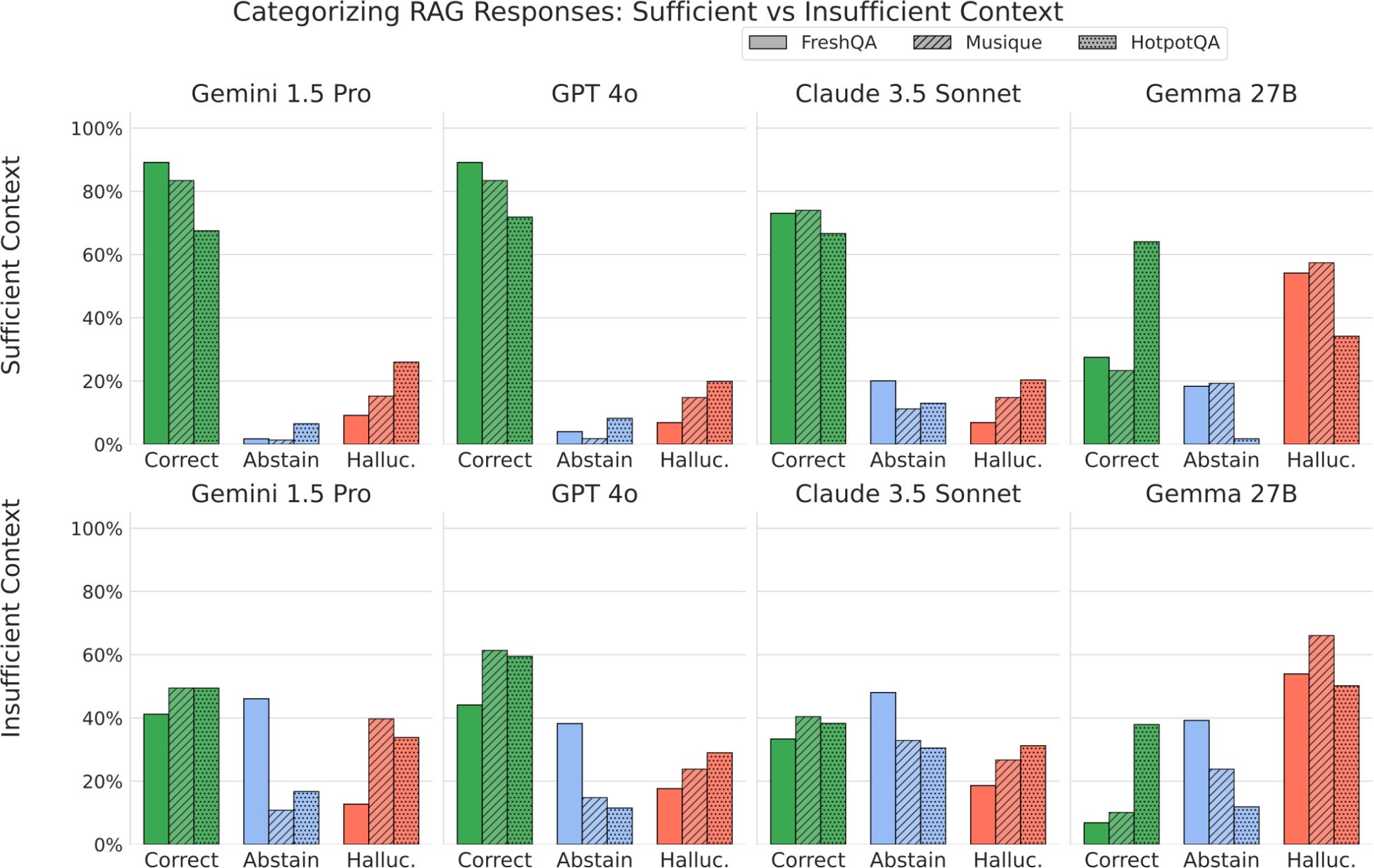
Şekil 3: Bağlam yeterliliğine göre ayrıştırılmış model performansı.
Yeterli bağlam sağlandığında modellerin doğruluk oranı yükselmekte ancak bağlam yetersiz olduğunda da önemli oranda doğru yanıt üretilebiliyor. Buna rağmen tüm modeller, özellikle de Gemma 27B gibi daha küçük boyutlu olanlar, bağlam yetersizliğinde halüsinasyon üretmeye daha yatkın oluyor.
Teoman Yiğit DUMAN
İTÜ Veri Bilimi ve Analitiği
❯ Reddit’ten Anthropic’e Dava!
Amerikan sosyal medya platformu Reddit, Anthropic firmasına dava açtı. İddiaya göre Anthropic, izinsiz bir şekilde Reddit’deki içerikleri 100 binden fazla kez erişip bu verileri topladı.

Açılan davaya göre Anthropic, kendi sohbet robotu Claude’u eğitebilmek için günlük 100 milyondan fazla kullanıcıya ait sohbetleri herhangi bir lisans anlaşması yapmadan kullandı. Reddit, sitedeki yorumlar ile yapay zekâ sistemlerini eğitmek için Google ve OpenAI ile ücretli anlaşmalar yapsa da Anthropic’in böyle bir anlaşma yapmadan verileri kullandığını iddia ediyor.
Reddit’in Baş Hukuk Sorumlusu Benjamin Lee, mahkemede yaptığı açıklamada “Yapay zekâ şirketlerinin veriyi nasıl kullanacakları hakkında net sınırlamalar olmadan kullanıcıların bilgilerini ve içeriklerini toplamasına izin verilmemeli.” dedi. Ayrıca Reddit kullanıcılarının mahremiyetini koruyacaklarını da ekledi.
Yakın zamanda 61,5 milyar dolar değerleme alan Anthropic, henüz konuyla ilgili bir açıklamada bulunmadı.
Şirketler kullanıcıların ürettiği verilerin değerini anladıkça lisans anlaşmaları daha da önem kazanıyor. Günümüzde veri, yeni petrol olmaya devam ediyor.
Berke BİLGİÇ
İTÜ Matematik Mühendisliği
❯ AgenticSeek: Manus AI’ye Yerel ve Açık Kaynak Bir Alternatif

Yapay zekâ asistanları hızla hayatımıza girerken kişisel verilerin gizliliği ve sistemlerin erişilebilirliği giderek daha önemli hale geliyor. AgenticSeek tam da bu noktada devreye giriyor.
Manus AI gibi güçlü sistemlerin sunduğu birçok özelliği tamamen yerel olarak ve tam kontrol ilkesiyle sunan AgenticSeek, açık kaynak dünyasında dikkat çeken yeni bir alternatif.
AgenticSeek Nedir?
AgenticSeek; bilgisayarınızda çalışan, internette gezinip bilgi toplayabilen, kod yazabilen ve karmaşık görevleri planlayabilen bir yapay zekâ asistanı. En önemli farkı şu: tüm bu işlemleri internet bağlantısı olmadan yalnızca kendi cihazınızda gerçekleştiriyor. Yani verileriniz dışarı çıkmıyor, üçüncü taraflarla paylaşılmıyor.
Öne Çıkan Özellikler
Tüm işlemleri tamamen yerel olarak gerçekleştiriyor.
İnternette gezinerek bilgi arayabiliyor ve içerikleri anlamlandırabiliyor.
Python, Go, Java gibi dillerde kod yazıp çalıştırabiliyor.
Karmaşık görevleri planlayabiliyor, çok adımlı süreçleri takip edebiliyor.
Sesli komutlarla çalışabiliyor ve konuşmaları yazıya dökebiliyor.
Neden Manus AI’ye Bir Alternatif?
Manus AI güçlü bir yapay zekâ arayüzü sunuyor ancak bulut tabanlı yapısı ve sınırlı erişimi nedeniyle bazı kullanıcılar için soru işaretleri oluşturabiliyor. AgenticSeek ise tamamen açık kaynak ve cihazınızda çalıştığı için hem şeffaf hem de kişisel veri güvenliği açısından çok daha kontrollü bir deneyim sunuyor.
Ahmet Sadık DEMİRCİ
İTÜ Matematik Mühendisliği
❯ ChatGPT'de Devrim: Kopyala-Yapıştır Devri Resmen Bitti!

OpenAI, yapay zeka sohbet robotu ChatGPT için kullanıcıların iş akışını kökten değiştirecek yeni bir özellik duyurdu. ChatGPT artık Google Drive, GitHub, SharePoint gibi üçüncü taraf uygulamalarla güvenli şekilde entegre çalışabiliyor; bu platformlardaki dosyalara ulaşabiliyor, canlı veri çekebiliyor, sohbet içinde aramalar yaptırılabiliyor.
ChatGPT, bağlı uygulamadan aldığı içerikleri sohbet içinde bağlam oluşturmak için veya daha tutarlı sonuçlar sunmak için kullanabilecek.

Kopyala-Yapıştır Derdine Son
Şu ana kadar kullanıcılar olarak bir belgeyi veya tabloyu analiz ettirmek için içeriğini kopyalayıp ChatGPT'ye yapıştırmak zorundaydık. Yeni özellik ise bu zorunluluğu ortadan kaldırıyor. Artık bir sunumun özetini çıkarmak, bir Excel tablosundan grafikler oluşturmak veya uzun bir dokümandaki kilit bilgileri bulmak için dosyayı doğrudan sohbete eklemek yeterli olacak.
Kimler Kullanabilecek?
Bu özellik; ilk aşamada ChatGPT'nin ücretli abonelikleri olan Plus, Team ve Enterprise kullanıcıları için kademeli olarak aktif edilecek. OpenAI, gelecekte daha fazla uygulama için "connector" desteği getirmeyi planladığını da belirtti.
Zehra AYDIN
İTÜ Matematik Mühendisliği
Bu haftanın haberlerinden etkilendiysen bir de gelecek haftayı gör! Okuduğun için çok şanslısın.
İyi haftalar…